Implementación Profunda de Sistemas RAG (Retrieval Augmented Generation): Componentes, Arquitectura y Optimización Avanzada
Introducción a los Sistemas RAG
Los Sistemas RAG (Retrieval Augmented Generation) representan una arquitectura emergente que combina técnicas de recuperación de información con modelos generativos para mejorar la capacidad de respuesta y la precisión en tareas de procesamiento de lenguaje natural. Estos sistemas integran bases de datos vectoriales o motores de búsqueda inteligentes con grandes modelos de lenguaje (LLMs) para generar respuestas contextualmente informadas y actualizadas, superando limitaciones típicas de los LLMs cuando se entrenan solo con datos estáticos.
En este artículo, abordaremos una implementación avanzada y completa de sistemas RAG, incluyendo sus principales componentes, arquitecturas recomendadas y técnicas de optimización para entornos productivos.
Arquitectura de un Sistema RAG
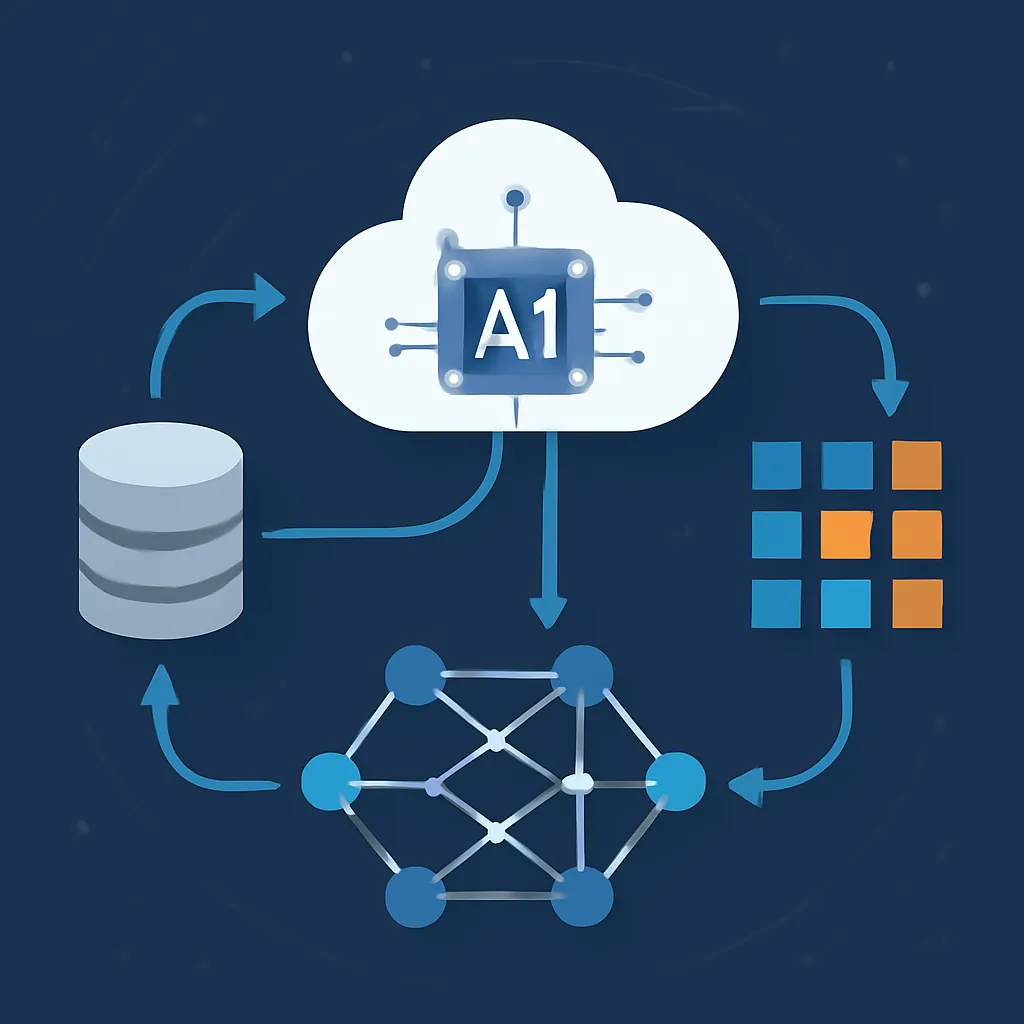
Un sistema RAG típico se compone de tres bloques fundamentales:
- Indexador y Motor de Recuperación: Normalmente una base de datos vectorial (como Pinecone, Weaviate o Milvus) que almacena embeddings o representaciones vectoriales del corpus de información.
- Módulo de Recuperación (Retriever): Recibe la consulta del usuario, la convierte a un vector (embedding) y recupera documentos relevantes en función de la similitud vectorial.
- Módulo Generativo (Generator): Usualmente un LLM que, usando los documentos recuperados, genera una respuesta coherente, contextualizada y relevante.
La interacción entre estos módulos puede describirse con el siguiente diagrama conceptual:
- Input de usuario → Embedding → Consulta al indexador → Documentos relevantes → Generación de respuesta final.
Componentes Técnicos y Elementos Clave
1. Creación y Gestión del Índice Vectorial
El primer paso es transformar el corpus textual en representaciones vectoriales que capturen el significado semántico para posteriores consultas eficientes:
- Embeddings: Utilización de modelos específicos (e.g.,
sentence-transformers,OpenAI embeddings) para vectorizar documentos. - Indexación: Elección del backend vectorial (Pinecone, Weaviate, Milvus) según escalabilidad, latencia y capacidad de filtrado.
- Actualización del índice: Estrategias de actualización incremental para mantener el índice actualizado sin downtime significativo.
from sentence_transformers import SentenceTransformer
import pinecone
# Inicializar modelo de embeddings
tf_model = SentenceTransformer('all-MiniLM-L6-v2')
# Inicializar cliente Pinecone
pinecone.init(api_key='YOUR_API_KEY', environment='us-west1-gcp')
index = pinecone.Index('document-index')
# Vectorizar documentos
corpus = ['Texto del documento 1', 'Texto del documento 2']
vectors = [tf_model.encode(text).tolist() for text in corpus]
# Indexar documentos con id
ids = ['doc1', 'doc2']
index.upsert(vectors=zip(ids, vectors))2. Recuperación de Documentos Relevantes
El módulo retriever convierte la consulta de usuario en embeddings y realiza una búsqueda de similitud:
def retrieve_documents(query, model, index, top_k=5):
query_vec = model.encode(query).tolist()
results = index.query(query_vec, top_k=top_k, include_metadata=True)
return [match['metadata']['text'] for match in results['matches']]
query = '¿Cuál es la arquitectura de sistemas RAG?'
docs = retrieve_documents(query, tf_model, index)
print(docs)3. Generación de Respuestas con LLMs
Una vez recuperados los documentos relevantes, se alimentan a un modelo generativo (e.g., GPT-4, Llama 2) para producir una respuesta enriquecida:
from transformers import pipeline
# Inicializar pipeline de generación (ejemplo con transformers)
generator = pipeline('text2text-generation', model='google/flan-t5-large')
# Construir prompt concatenando contexto y pregunta
def build_prompt(contexts, question):
context_text = '\n'.join(contexts)
return f"Contexto: {context_text}\nPregunta: {question}\nRespuesta:"
prompt = build_prompt(docs, query)
response = generator(prompt, max_length=200)
print(response[0]['generated_text'])Optimización y Mejores Prácticas
1. Estrategias para Mejorar la Calidad de los Resultados
- Re-rankers: Utilizar modelos como Cross-encoders para recalificar la relevancia de documentos recuperados y ordenar mejor la entrada al generador.
- Context Windowing: Limitar la cantidad de documentos o tokens pasados para ajustarse a las restricciones de entrada del LLM sin perder contexto.
- Fusión de múltiples fuentes: Combinar información de diversos índices o bases de datos (p.ej., bases internas + web) para mayor cobertura.
2. Arquitectura Escalable y Robustez
- Uso de contenedores y servicios orquestados (Docker + Kubernetes) para desplegar cada módulo por separado con escalabilidad horizontal.
- Implementación de cachés para consultas frecuentes y almacenamiento en memoria para reducir latencias.
- Monitorización activa con métricas clave: latencia, tasa de error, calidad de respuesta (mediante feedback de usuario o métricas automáticas).
3. Ejemplo de Pipeline Orquestado (Simplificado en YAML para Kubernetes)
apiVersion: apps/v1
kind: Deployment
metadata:
name: rag-retriever
spec:
replicas: 3
selector:
matchLabels:
app: rag-retriever
template:
metadata:
labels:
app: rag-retriever
spec:
containers:
- name: retriever
image: mi-registro/rag-retriever:latest
ports:
- containerPort: 8000
resources:
limits:
cpu: "2"
memory: "4Gi"
requests:
cpu: "1"
memory: "2Gi"Conclusiones y Futuras Direcciones
Los sistemas RAG ofrecen una arquitectura poderosa para superar las limitaciones estáticas de los LLMs, incorporando bases de conocimiento dinámicas y actualizables. La clave para su éxito radica en la correcta integración, la optimización en la recuperación y la generación, y la capacidad de desplegar servicios escalables y monitorizados.
Las tendencias futuras incluyen la incorporación de mecanismos de feedback activo para adaptación continua, mejoras en la eficiencia computacional mediante modelos más ligeros y el uso de arquitecturas multimodales para enriquecer aún más las capacidades del sistema.