Implementación Profunda de Sistemas RAG (Retrieval Augmented Generation): Componentes y Optimización Avanzada
Exploramos a fondo la arquitectura, componentes clave y técnicas de optimización para construir sistemas RAG escalables y de alta precisión.
Introducción a los Sistemas RAG
Los Sistemas Retrieval Augmented Generation (RAG) representan un paradigma revolucionario en la generación de texto, donde la producción de respuestas se enriquece y fundamenta mediante la consulta dinámica a documentos o bases de conocimiento externas. Esta arquitectura combina la potencia de modelos generativos de lenguaje con motores de búsqueda de alta eficiencia, dando lugar a aplicaciones con respuestas más precisas, actualizadas y explicables.
El reto principal es integrar de manera eficiente y robusta los módulos de recuperación de información y generación condicional, garantizando baja latencia, alta escalabilidad y precisión semántica.
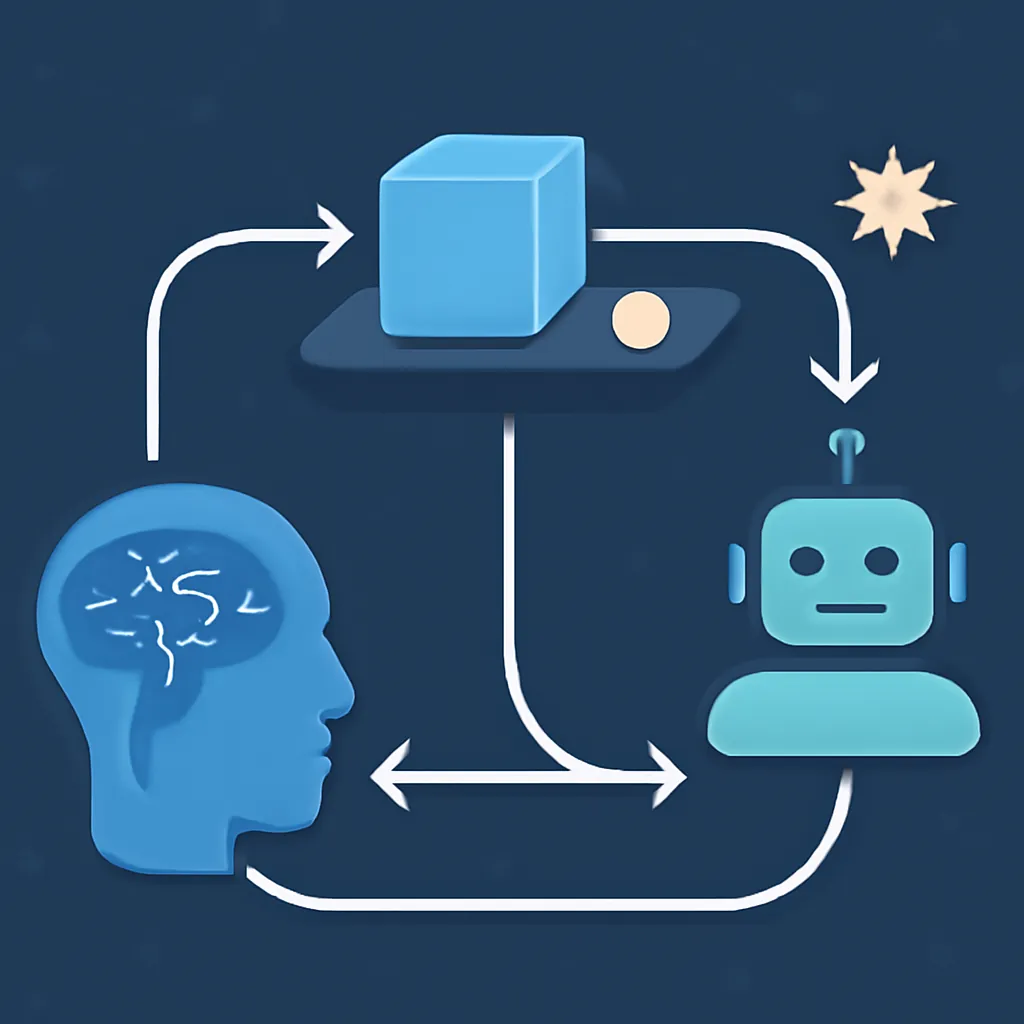
Arquitectura General del Sistema RAG
Un sistema RAG típico consta de tres bloques funcionales principales:
- Encoder de Consulta: Representa la pregunta o prompt del usuario en un espacio vectorial semántico.
- Motor de Recuperación (Retriever): Busca en una base de datos vectorial los documentos o fragmentos más relevantes al vector consulta.
- Modelo Generativo (Generator): Condiciona su salida textual a los documentos recuperados para producir respuestas fundamentadas.
Esta estructura puede implementarse implementándose modelos dual encoders para búsqueda vectorial y modelos autoregresivos condicionados o encoder-decoder para generación.
Componentes Técnicos Detallados
1. Indexación y Bases de Datos Vectoriales
La elección y configuración de la base de datos vectorial es crítica. Herramientas como Pinecone, Weaviate o Milvus permiten:
- Indexar embeddings generados por modelos como
SentenceTransformeroOpenAI-Embedding. - Realizar búsquedas eficientes de vecinos más cercanos (ANN) en grandes volúmenes de fragmentos documentales.
- Escalar horizontalmente con particionamiento y replicación.
Ejemplo de creación e inserción en Milvus (Python):
from pymilvus import connections, utility, FieldSchema, CollectionSchema, DataType, Collection
# Conexión
connections.connect(alias="default", host="127.0.0.1", port="19530")
# Definición esquema
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=768)
]
schema = CollectionSchema(fields, "Document embeddings")
# Crear colección
collection = Collection(name="docs_vector", schema=schema)
# Insertar embeddings
import numpy as np
embeddings = np.random.random((10, 768)).tolist()
collection.insert([list(range(10)), embeddings])2. Modelos de Embedding para Queries y Documentos
Los embeddings deben capturar la semántica profunda. Modelos recomendados:
- Sentence-BERT (multilingüe o domain-specific para textos técnicos o legales).
- OpenAI text-embedding-ada-002 para mayor compactación y precisión general.
Es aconsejable realizar fine-tuning o adaptación usando triplet loss o contrastive learning para mejorar la calidad en el dominio objetivo.
3. Modelos Generativos Condicionados
Los modelos generativos se alimentan con el prompt original concatenado o estructurado junto con los textos recuperados. Opciones comunes:
- T5 / BART: excelente para generación condicional y comprensión.
- GPT-3 / GPT-4 mediante APIs, con pocos-shot prompting para mantener coherencia con documentos.
Ejemplo Código para Pipeline RAG con LangChain + Milvus + OpenAI
Ejemplo simplificado del pipeline de recuperación y generación:
from langchain.vectorstores import Milvus
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.llms import OpenAI
from langchain.chains import RetrievalQA
# Inicializar embeddings y vectorstore
embeddings = OpenAIEmbeddings()
vectorstore = Milvus(
collection_name="docs_vector",
embedding_function=embeddings.embed_query,
connection_args={"host": "localhost", "port": "19530"}
)
# Inicializar LLM
llm = OpenAI(model_name="gpt-4", temperature=0)
# Construir cadena RAG
retriever = vectorstore.as_retriever(search_kwargs={"k": 5})
qa_chain = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=retriever)
# Ejecución consulta
query = "¿Cuáles son las últimas técnicas en medicina regenerativa?"
respuesta = qa_chain.run(query)
print(respuesta)Optimización Avanzada y Consideraciones
- Actualización Dinámica de Índices: Automatizar la ingesta y actualización para mantener la base documental vigente, usando NLP para fragmentación y etiquetado semántico.
- Filtrado y Re-ranking: Aplicar algoritmos de re-ranking (e.g., Cross-Encoder BERT) para aumentar precisión filtrando candidatos recuperados antes de la generación.
- Reducir Latencia: Cachear embeddings frecuentes, usar batching en llamadas a LLM, y desplegar servicios con GPUs aceleradas.
- Control de Calidad de Respuestas: Incorporar validación automática de factualidad y confianza para evitar generación de contenido no verificado.
- Escalabilidad: Orquestar componentes con Kubernetes + GPU pods, autoescalado y monitorizar con Prometheus y Grafana.
Conclusiones y Mejores Prácticas
Los sistemas RAG representan un modelo poderoso para generar contenido útil y fundamentado, integrando las mejores capacidades de búsqueda y generación. Las claves para su éxito residen en:
- Elección adecuada de base vectorial y embeddings alineados al dominio.
- Pipeline modular y automatizado para aggiornamiento constante del corpus y modelo.
- Optimización de infraestructura y latencia para experiencia fluida.
- Incorporación de filtros y validaciones para garantizar calidad y responsabilidad.
Con esta combinación, los sistemas RAG se posicionan como el futuro de asistentes inteligentes, motores de búsqueda conversacional y generación documental automatizada.